DeepSeek识图模式全量上线!图文交互能力实测与V4.1前瞻

一、DeepSeek识图模式是什么?
DeepSeek识图模式是DeepSeek大模型原生搭载的图像理解功能,允许用户上传图片后由AI自动识别、解析、推理。2026年6月18日,DeepSeek多模态研究员Xiaokang Chen确认识图模式已在网页和App端正式全量上线,与"快速模式""专家模式"并列作为一级交互入口。
二、DeepSeek识图模式能做什么?
识图模式支持图片内容理解、联网增强问答、技术截图解析等核心能力,可精准识别图像中的文字、表格、数学公式等结构化信息,并理解场景氛围、物体关系、空间逻辑甚至文化语境。实测中,普通物体识别、地标建筑判断、数学题图解析表现稳定,且支持自主验算。
三、上线历程:从“闭眼”到“睁眼”的两个月
DeepSeek识图模式的上线并非一帆风顺,其时间线清晰反映了国产大模型在多模态领域的探索节奏:
时间节点 | 事件 | 状态 |
|---|---|---|
2026年4月19日 | 识图模式首次灰度测试上线 | 灰度测试 |
2026年4月29日 | 多模态研究员陈小康在X平台发布"Now, we see you"推文,鲸鱼摘下眼罩 | 官方预热 |
2026年4月30日 | 因第三方反代滥用+算力不足,功能暂停 | 功能下线 |
2026年6月15日 | 灰度测试重新出现 | 二次灰度 |
2026年6月18日 | 网页+App端全量上线 | 正式发布 |
从灰度到全量的近两个月时间里,DeepSeek主要解决了两个核心问题:一是反代滥用的防护机制,二是识图模型的精度提升。6月16日完成的510亿元首轮融资(估值接近4000亿元),为算力扩容提供了坚实支撑。
四、核心能力:不只是OCR,而是深度图像理解
与市面上多数“上传图片→提取文字”的OCR工具不同,DeepSeek强调这是深度图像理解——模型不仅能读取画面中的文字,还能理解场景氛围、物体关系、空间逻辑甚至文化语境。
已验证的核心能力:
图像语义理解:识别画面中的物体、人物、场景及文化语境。
空间与逻辑推理:处理立方体拼合、迷宫导航、路径追踪等拓扑任务。
技术文档解析:将网页截图转为可交互HTML、复杂表格转Markdown、流程图解读为文本描述。
数学题图解析:识别数学公式并自主完成验算。
自我修正与多步推理:开启"深度思考"模式后可进行自问自答式纠错。

明确不支持的功能:
图像生成、视频理解或跨模态生成
以图搜图、商品比价、二维码识别
多图对比分析(当前仅支持单图上传)
联网搜索增强(知识库截止至2025年5月)
五、技术架构:“Thinking with Visual Primitives”
DeepSeek识图模式基于“Thinking with Visual Primitives(以视觉原语思考)”核心框架,通过点、边界框等视觉原语进行推理。这一技术路线的显著优势在于token消耗极低——800×800图像仅约90 tokens,约为GPT/Claude的1/10。当前识图模式采用"V4文本主干+视觉编码器对齐"的挂载式架构,属视觉语言模型(VLM),非原生多模态生成。
六、V4.1前瞻:从“预热”到“正式版本”
识图模式的全量上线被业界普遍视为V4.1完整多模态版本发布前的预热信号。据多方消息,V4.1将带来三大核心升级:
模态 | 编码器 | 参数量 | 功能 |
|---|---|---|---|
文本 | DeepSeek原生LLM | 1.6T MoE | 自然语言理解与生成 |
图像 | ViT-22B | 22B | 图像理解、OCR、图表解析 |
音频 | Whisper-Large-v4 | ~1.5B | 语音转文本、音频理解 |
ViT-22B是目前开源视觉编码器中参数量最大的版本之一,远超常见的ViT-L/14(304M)。这意味着V4.1在图像理解精度上将大幅超越当前识图模式的水平。此外,V4.1还将原生支持MCP协议(准确率94.7%,延迟1.1秒),并配套推出企业级工具链集成。
七、通过OpenClaw部署助手接入DeepSeek模型
对于希望将DeepSeek大模型能力集成到自有系统或工作流中的开发者和企业用户,私有化部署是重要选项。「OpenClaw部署助手」是一款开源的AI智能体框架,支持多智能体协作、多渠道接入与私有化部署,可无缝对接DeepSeek大模型作为核心推理引擎。具体步骤:
1. 安装OpenClaw部署助手:点击下方按钮直接获取安装包。
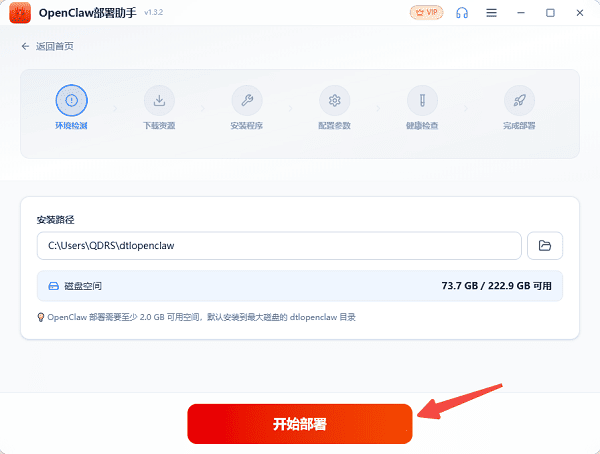
2. 运行配置向导:安装完成后打开软件,点击“开始部署”,按提示完成基础环境配置。
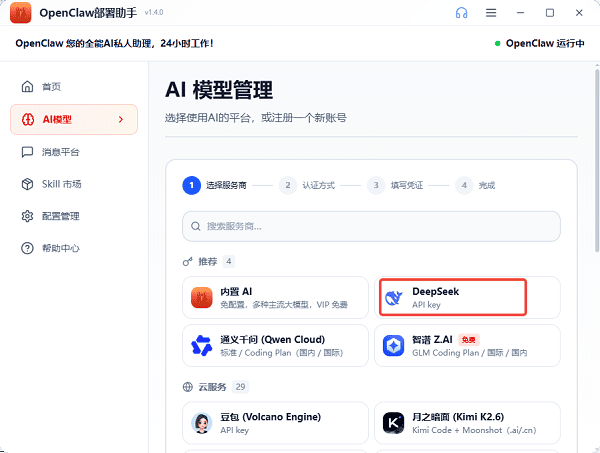
3. 选择模型服务商:在“AI模型管理”界面中,从推荐列表里选择DeepSeek作为服务商。
4. 选择认证方式:选择“DeepSeek API key”认证方式,点击进入下一步。
5. 填写API凭证:在“API Key”输入框中填入从DeepSeek官网获取的API密钥;若暂无账号,可点击链接前往DeepSeek注册页面申请。

6. 指定模型版本:在“模型名称”输入框中填写所需调用的模型版本,如 deepseek V4,也可使用默认推荐模型。
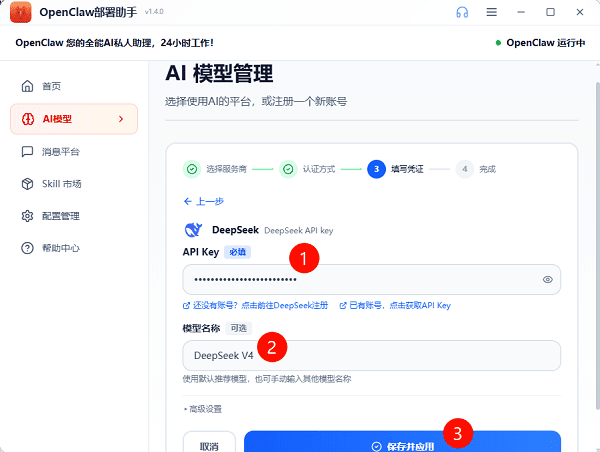
7. 保存并启用:点击“保存并启用”按钮,完成模型配置。
注意:DeepSeek API的调用需确保账号内有足够余额,新注册用户通常有一定额度的免费体验额度。企业级大规模调用建议提前充值并关注官方定价策略。
八、国产多模态竞争格局
识图模式的全量上线使DeepSeek在国产大模型多模态竞赛中占据关键位置:
模型 | 图像理解 | 音频理解 | MCP支持 | 上下文 | 定价 |
|---|---|---|---|---|---|
DeepSeek V4.1 | ViT-22B ✅ | Whisper-v4 ✅ | 原生 ✅ | 128K+ | 极低 |
MiniMax M3 | 多模态MoE ✅ | — | 适配层 | 1M | 低 |
GLM-5.2 | 图像 ✅ | — | — | 1M | MIT开源 |
Qwen3.7-Max | 多模态 ✅ | — | — | — | 中 |
DeepSeek V4.1将是国产首个原生MCP+全模态(文本+图像+音频)的大模型,这一组合在国产竞品中尚无先例。
九、常见问题解答
Q1:DeepSeek识图模式和V4.1的识图有什么区别?
当前识图模式使用的是V4级别的视觉编码器,V4.1将升级为ViT-22B——参数量提升数十倍,图像理解精度将大幅跃升。当前版本更像"预热",V4.1才是"正式版本"。
Q2:识图模式支持哪些图片格式?
支持JPG、PNG格式,单张图片不超过100MB。HEIF等部分格式暂不支持上传。
Q3:深度思考模式下识图为什么很慢?
开启"深度思考"模式后,模型会进行自问自答式纠错和多步推理,响应时间可达4分钟以上,适合高精度需求但不适合实时交互。日常场景建议使用普通模式。