DeepSeek-V4 Flash 本地部署全攻略 全网最简单

随着大语言模型(LLM)技术的飞速演进,DeepSeek 凭借其卓越的性能与极致的性价比,已成为开发者与 AI 爱好者的首选。而最新发布的DeepSeek-V4 Flash版本,更是通过模型蒸馏与架构优化,在保持强大逻辑推理能力的同时,极大地降低了对硬件的门槛。
为了帮助大家快速将这款“性能小钢炮”搬进个人电脑,本文将详细讲解 DeepSeek-V4 Flash 的本地部署流程,并重点推荐一款能让部署效率翻倍的神器——OpenClaw 部署助手。
一、为什么选择本地部署 DeepSeek-V4 Flash?
本地部署不仅是为了“极客感”,更具有实际的应用价值:
1. 隐私安全:所有对话数据均在本地处理,无需上传云端,彻底告别隐私泄露风险。
2. 离线可用:在无网络环境下依然能稳定运行,成为你的“随身大脑”。
3. 零推理成本:除了初始的电力与硬件投入,后续调用模型不再产生按 Token 计费的费用。
DeepSeek-V4 Flash 针对速度进行了专项优化,即使是中等配置的电脑(如 16GB 内存或 8GB 显存的显卡),也能跑出极佳的响应速度。
二、传统部署方式的局限性
通常情况下,本地部署 AI 模型需要经历以下繁琐步骤:
安装 Python 环境并配置复杂的环境变量;
部署 Ollama 或 LM Studio 等中间件;
手动从 Hugging Face 或 ModelScope 下载动辄几十 GB 的权重文件;
处理各种驱动不兼容、CUDA 报错等玄学问题。
对于非技术背景的用户来说,这道“门槛”往往足以劝退 90% 的初学者。
三、使用 OpenClaw 部署助手一键部署
为了简化上述流程,OpenClaw 部署助手应运而生。它是一款专门为普通用户设计的 AI 落地工具,将原本复杂的命令行操作封装成了极简的图形化界面。
使用 OpenClaw 部署 DeepSeek-V4 Flash 的步骤:
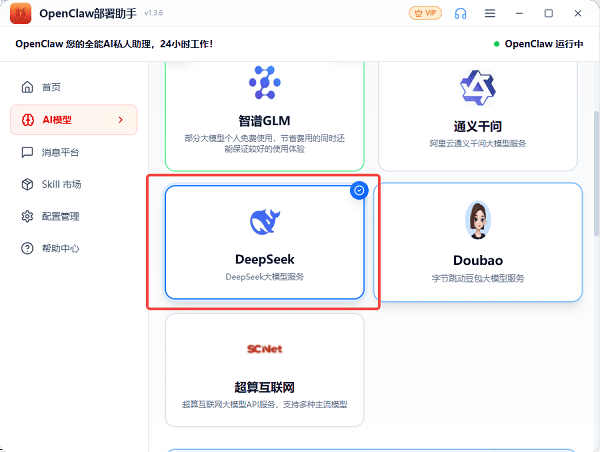
1. 下载安装openclaw部署助手,打开软件点击【AI模型】页面,点击“DeepSeek”;
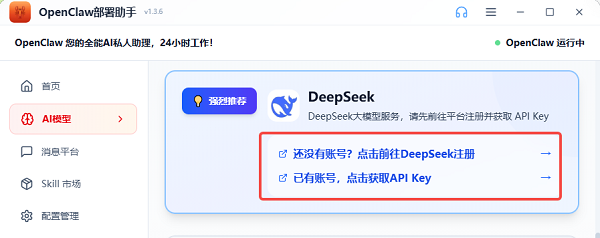
2. 滑动鼠标滚轮到下方的“DeepSeek账号注册”没有账号就点击上方“还没有账号?点击前往DeepSeek注册”如有账号就点击下方“已有账号点击获取API Key”;
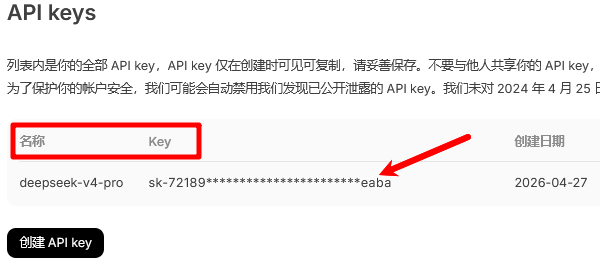
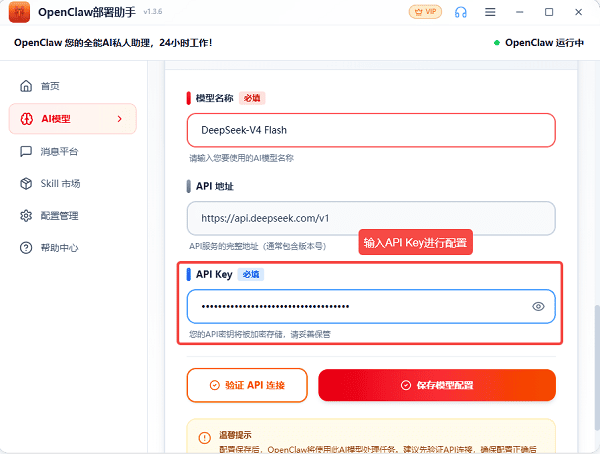
3. 注册或者是登录账号后,获取到新的“DeepSeek-V4”模型,创建“API Key”后复制“Key”,然后滑动到“模型配置”处,输入“API Key”点击“保存模型配置”即可;
四、 硬件配置参考建议
虽然 DeepSeek-V4 Flash 极其轻量化,但为了获得流畅体验,建议参考以下配置:
入门级:16GB RAM + 核显。可流畅运行量化后的版本,响应速度约每秒 3-5 个字。
进阶级:RTX 3060 (12GB 显存) 或以上。可实现“秒出答案”的快感。
推荐级:Mac M2/M3 系列(统一内存 16GB 以上)。得益于金属加速,体验极佳。
DeepSeek-V4 Flash 的出现打破了“大模型必须烧钱”的固有印象,而OpenClaw部署助手则填补了技术与普通用户之间的鸿沟。
如果你一直渴望拥有一个专属的、私密的 AI 助手,却被繁琐的代码挡在门外,那么现在就是最好的时机。无需成为程序员,只需点点鼠标,DeepSeek-V4 Flash 就能在你的电脑里为你出谋划策。