OpenClaw × Peekaboo v3发布:视觉识别与自动化能力实测

OpenClaw最新上线的Peekaboo v3,本质上是一套 AI “视觉感知”能力扩展。它由OpenClaw社区开发者与自动化生态贡献者共同推进,核心目标是让 AI Agent 不再只依赖文字,而是能够真正“看见屏幕”“理解界面”“分析截图”。
一、Peekaboo v3是什么?
Peekaboo v3 并不是单独某一个商业产品,而是由 OpenClaw 社区开发者与 AI Agent 自动化方向贡献者持续推进的视觉模块项目。它的核心思路其实很明确:让 AI Agent 拥有“视觉能力”。此前很多 AI Agent 最大的问题在于:
会推理
会聊天
会调用工具
但不会:
看电脑屏幕
理解GUI界面
判断按钮位置
分析应用窗口
而 Peekaboo v3 的目标,就是补齐这一块。
图源:36氪
二、Peekaboo v3 到底是什么?
简单理解:Peekaboo v3 = OpenClaw 的“视觉层”。它可以让 AI:
查看当前屏幕
读取窗口内容
分析截图
判断界面状态
理解软件布局
这也是为什么现在很多开发者开始把 Peekaboo 称为:“AI Agent 的眼睛”。与传统OCR相比,Peekaboo 更偏向:
AI视觉理解
GUI分析
上下文判断
而不仅仅是简单识别文字。
三、Peekaboo v3有哪些重点能力?
1、屏幕捕获能力
Peekaboo v3 可以直接读取:
当前桌面
指定窗口
软件界面
浏览器页面
然后交给视觉模型进行分析。
2、视觉问答(Vision QA)
这是目前社区热度最高的功能之一。例如:
“当前窗口报了什么错?”
“网页按钮在哪?”
“这个界面应该点击哪里?”
AI 都可以基于截图进行判断。

图源:GitHub
3、GUI界面理解
Peekaboo v3 的重点并不是“截图”。而是AI理解GUI。例如:
判断按钮位置
识别菜单栏
理解软件状态
分析窗口层级
这也是 AI 自动操作电脑的重要基础。
4、MCP Server 支持
Peekaboo v3 目前已经支持:
CLI
MCP Server
这意味着它不仅能单独运行,还能:
接入 OpenClaw
加入 Agent 工作流
结合 Skill 系统使用
四、运用Peekaboo v3
Peekaboo v3本身涉及MCP、Vision模型、Skill依赖和Agent配置,如果完全手动部署,其实对新手并不友好。因此建议大家可以借助“OpenClaw部署助手”来完成配置。尤其是在安装 Peekaboo Skill 的时候,会比传统命令行简单很多。操作步骤:
1、打开OpenClaw部署助手,完成环境部署。
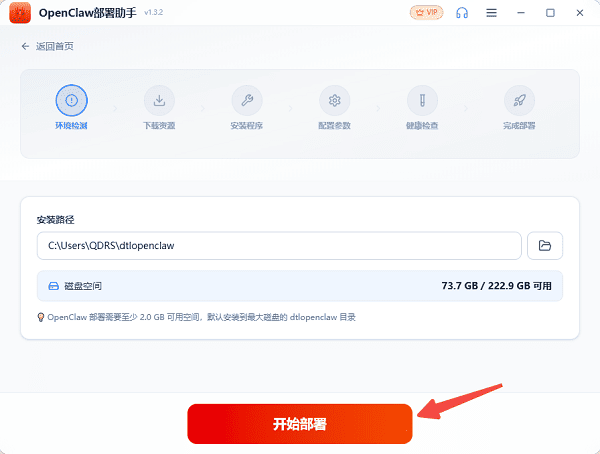
2、点击左侧“Skill市场”,进入后可以看到海量的Skill。
3、点击搜索Peekaboo,即可找到对应视觉 Skill。
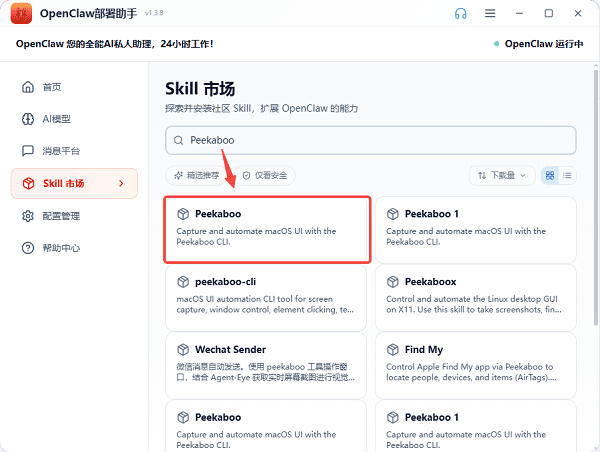
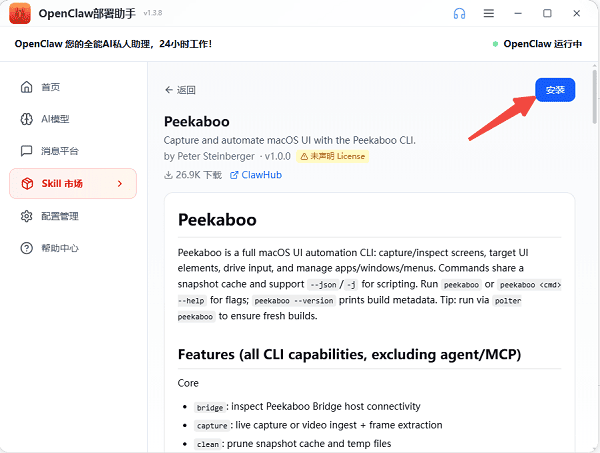
4、点击后即可进入详情页,再点击“安装”按钮即可。
5、安装完成后,回到首页,点击“打开聊天”,在“技能”一栏可以看到Peekaboo已开启。
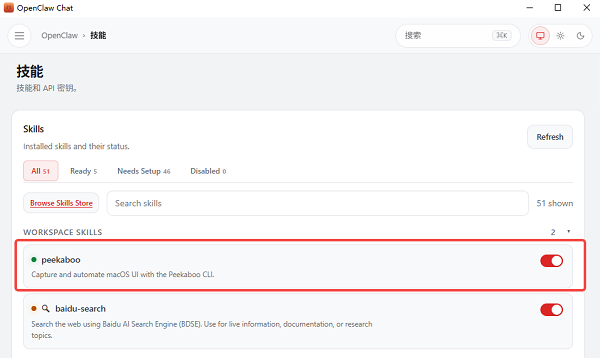
6、这时你就可以开始进行视觉问答了。
五、常见问题解答
Q:Peekaboo v3相比v2最明显的变化是什么?
Peekaboo v3最核心的变化是技能系统重构与任务调度优化。相比v2版本,v3在模块化能力、并行执行效率以及扩展接口统一性方面都有明显提升,使整体运行更加稳定且易扩展。
Q:升级到Peekaboo v3是否需要重新部署环境?
一般情况下需要进行环境适配或重新部署依赖,但如果使用OpenClaw部署助手,可以通过“一键部署”功能自动完成大部分配置,无需手动处理复杂依赖关系。
Q:Peekaboo v3是否支持扩展自定义技能?
支持。v3版本强化了扩展接口标准化能力,允许开发者通过统一API结构接入自定义技能模块,实现功能扩展与组合调用。
Peekaboo v3 的上线,其实代表着 OpenClaw 正在从传统 AI 助手,逐渐进化为真正具备视觉理解能力的 AI Agent 平台。未来很多网页操作、软件控制甚至桌面自动化任务,都可能逐渐交给 AI 完成。而对于普通用户来说,如果不想从命令行开始研究复杂环境,通过OpenClaw部署助手安装Peekaboo Skill,会是目前体验视觉 Agent 能力更简单直接的方式。